Neerali Acharya
7 years shipping production backend systems. I build AI that works at scale — not just in demos.
From the trenches
I Built a RAG Pipeline. Then Reality Hit. Here's Every Problem I Solved
The three production bugs no RAG tutorial warns you about — non-deterministic outputs, hallucination, and context loss in multi-turn chats — and exactly how I fixed each one.
Read on Medium →AI systems
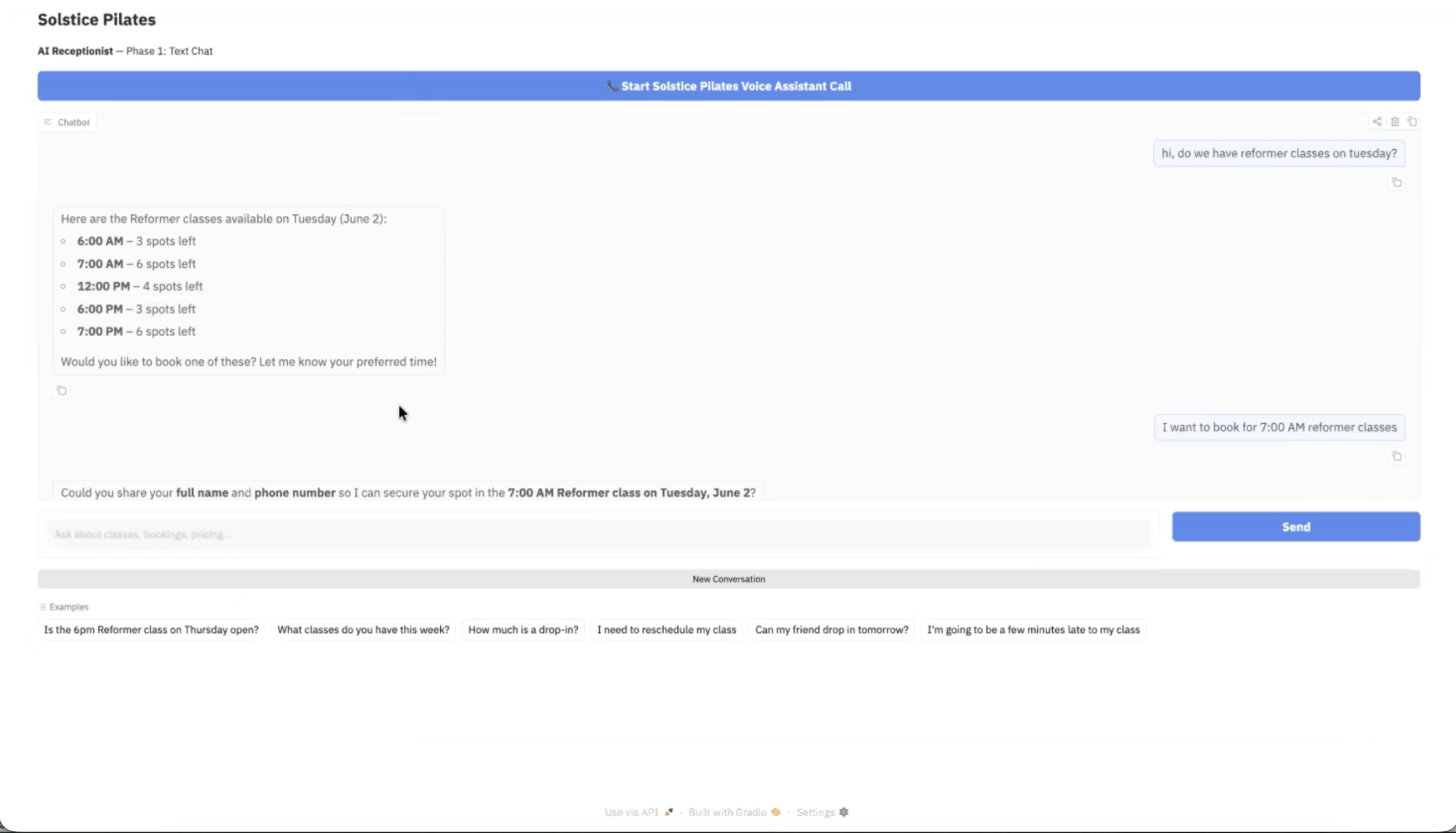
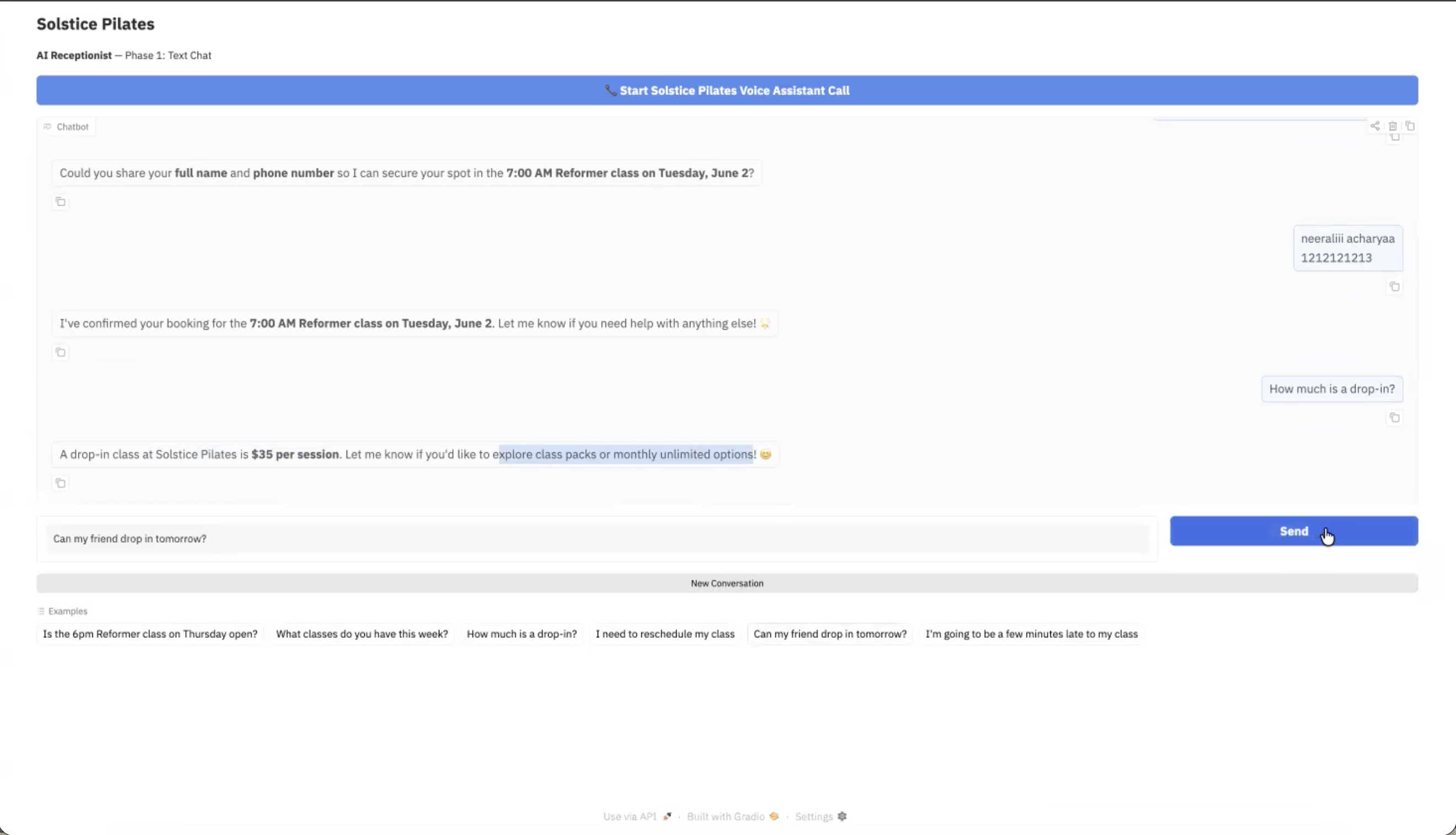
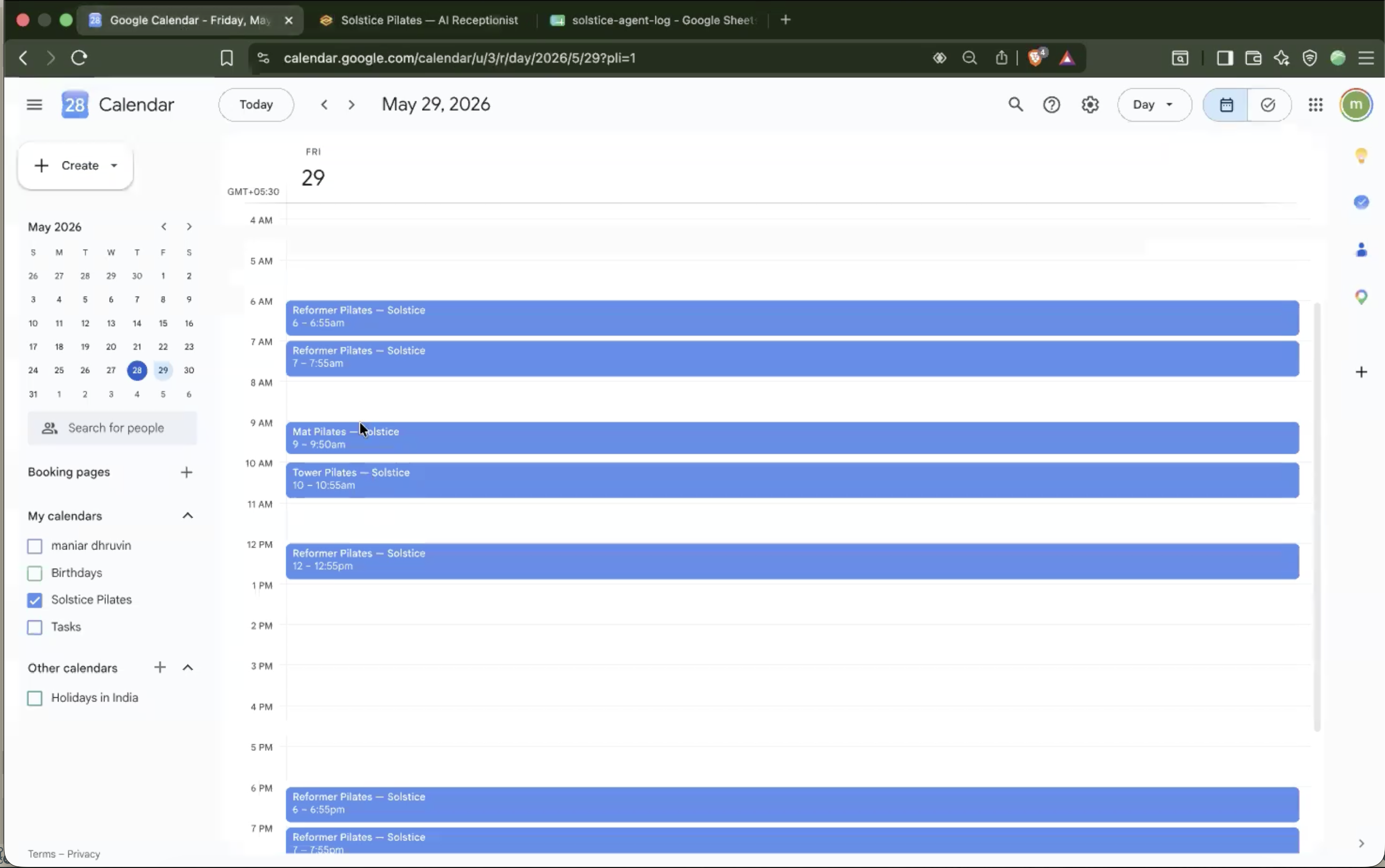
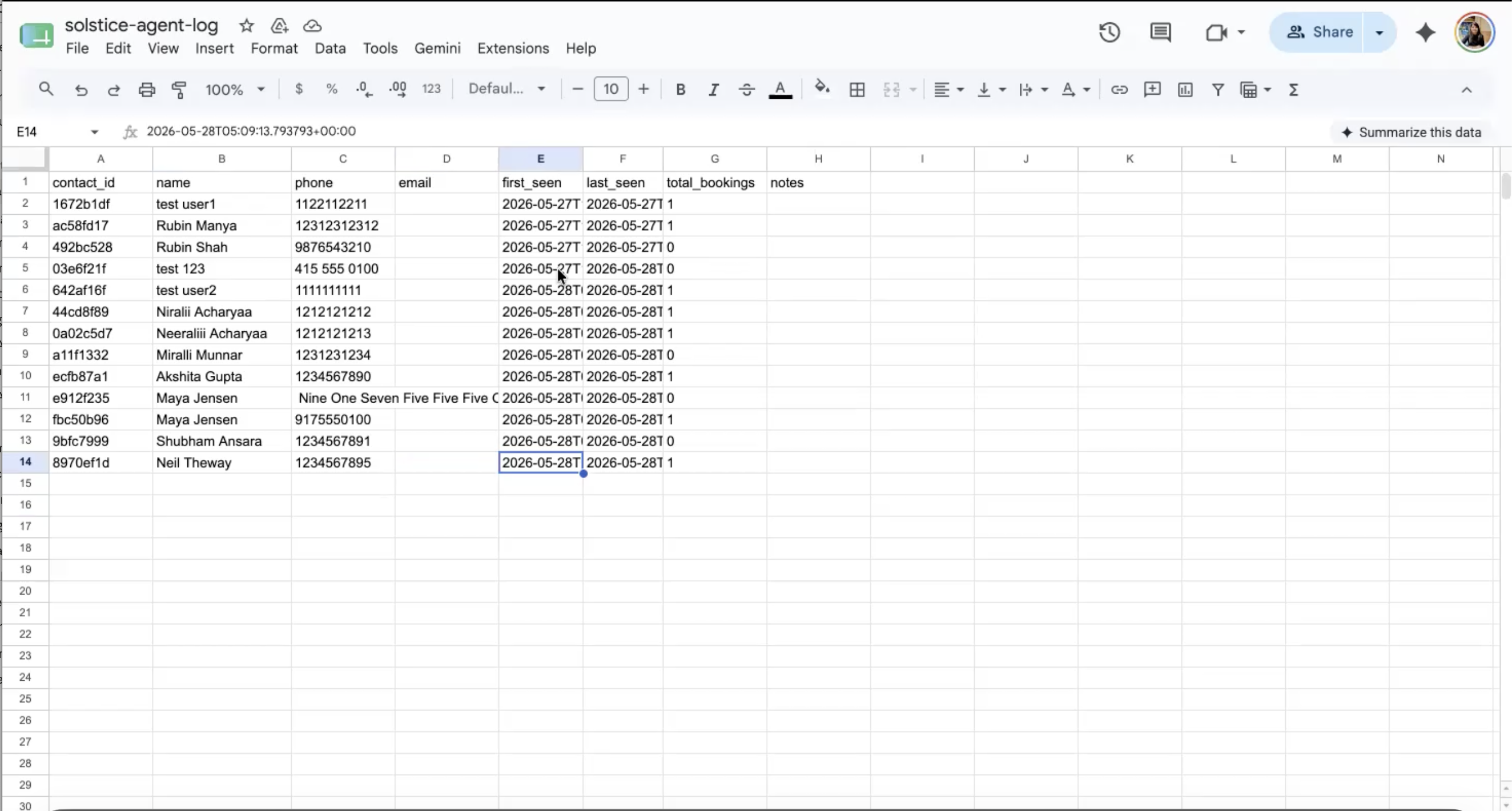
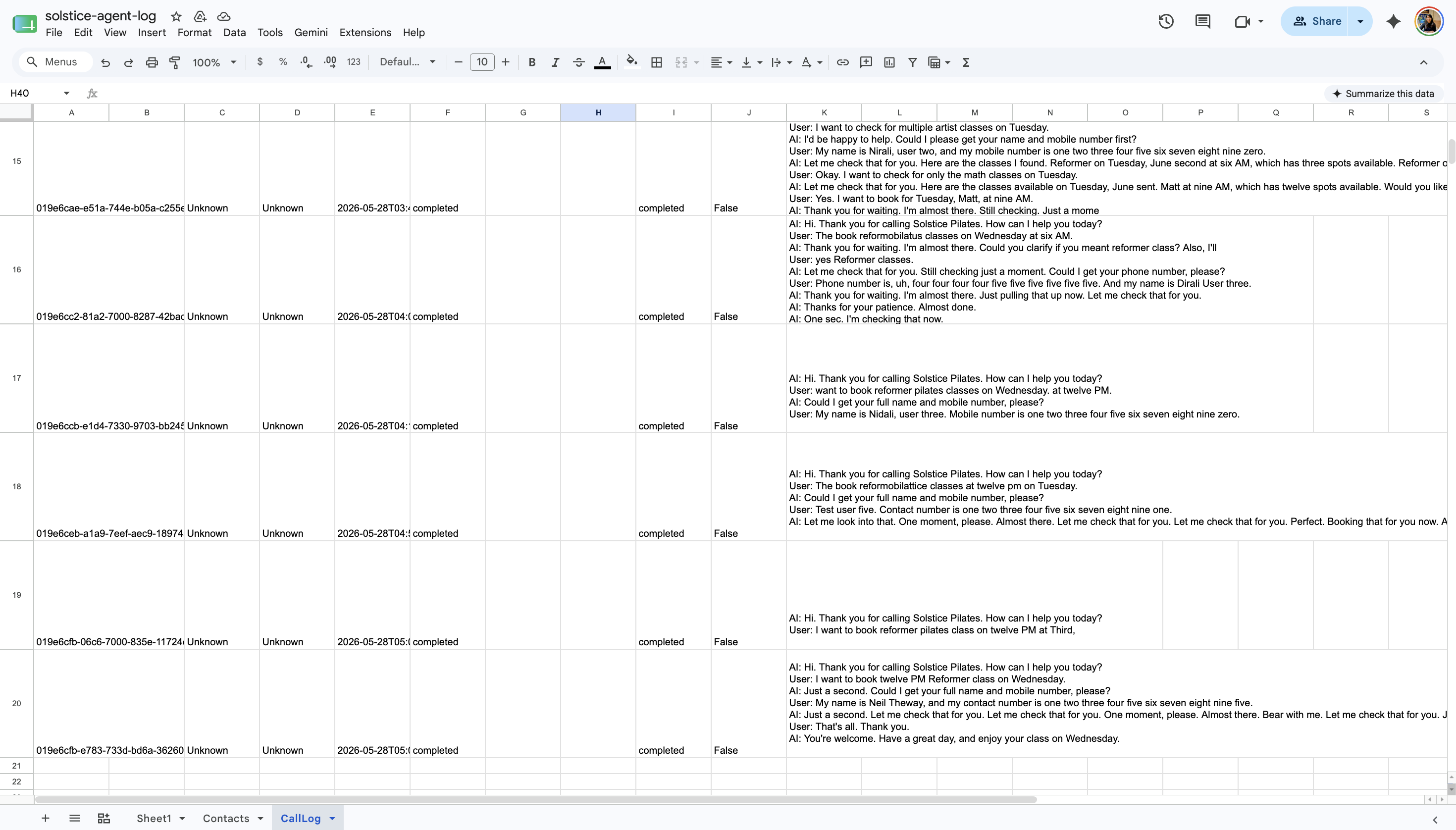
AI Receptionist
Chat and Voice Agent
Autonomous AI receptionist for a Pilates studio — handles inbound voice calls, bookings, rescheduling, and pricing. Built with a 4-model LLM fallback chain for uninterrupted service under API failures.
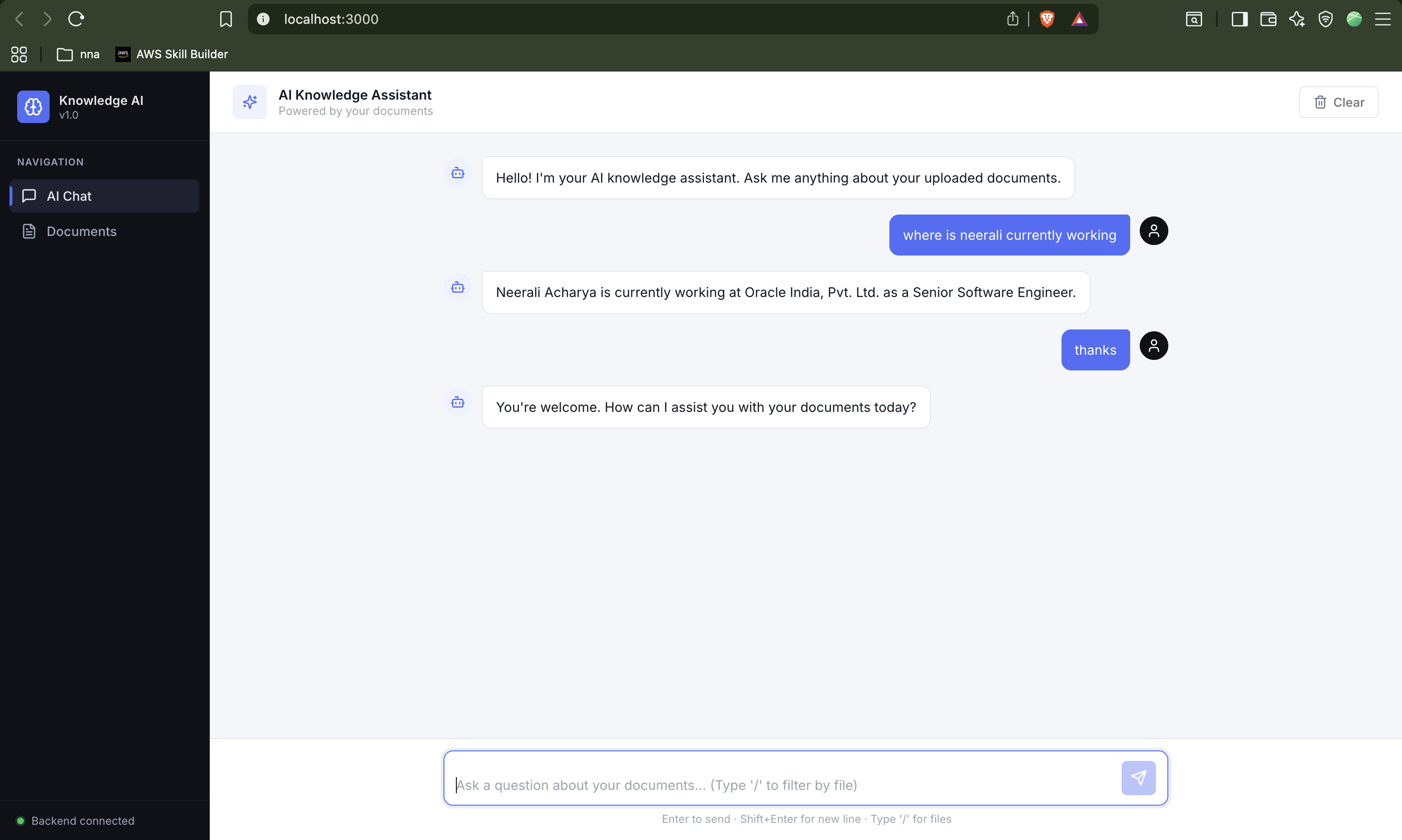
AI Doc Assist —
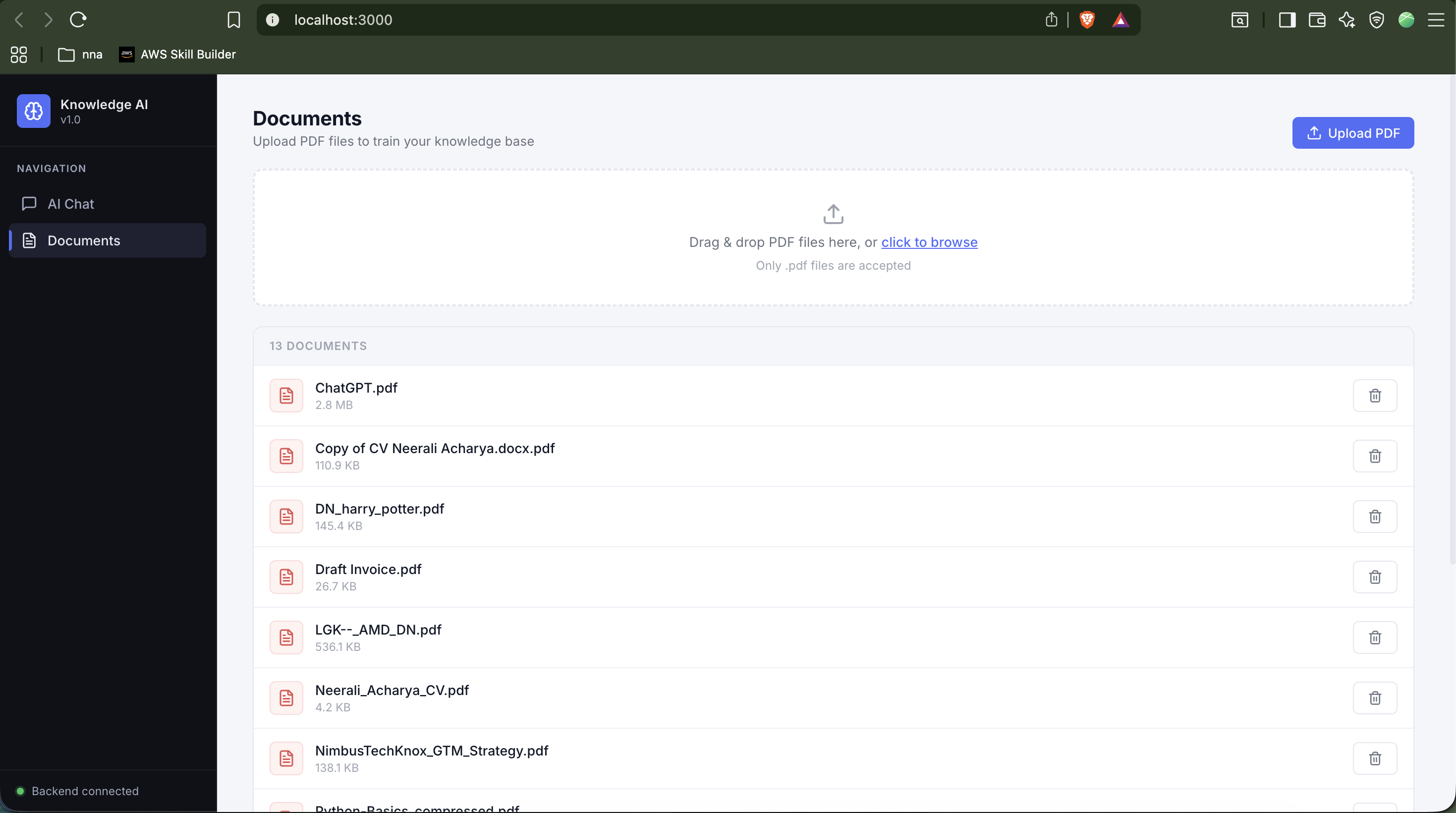
Knowledge Assistant
Production-grade RAG platform for internal documentation. Upload any PDF, query it conversationally — every answer is grounded with doc name + page-level source traceability. Built RAGAS evaluation harness measuring Faithfulness 0.88, Answer Relevancy 0.76, Context Precision 0.81.
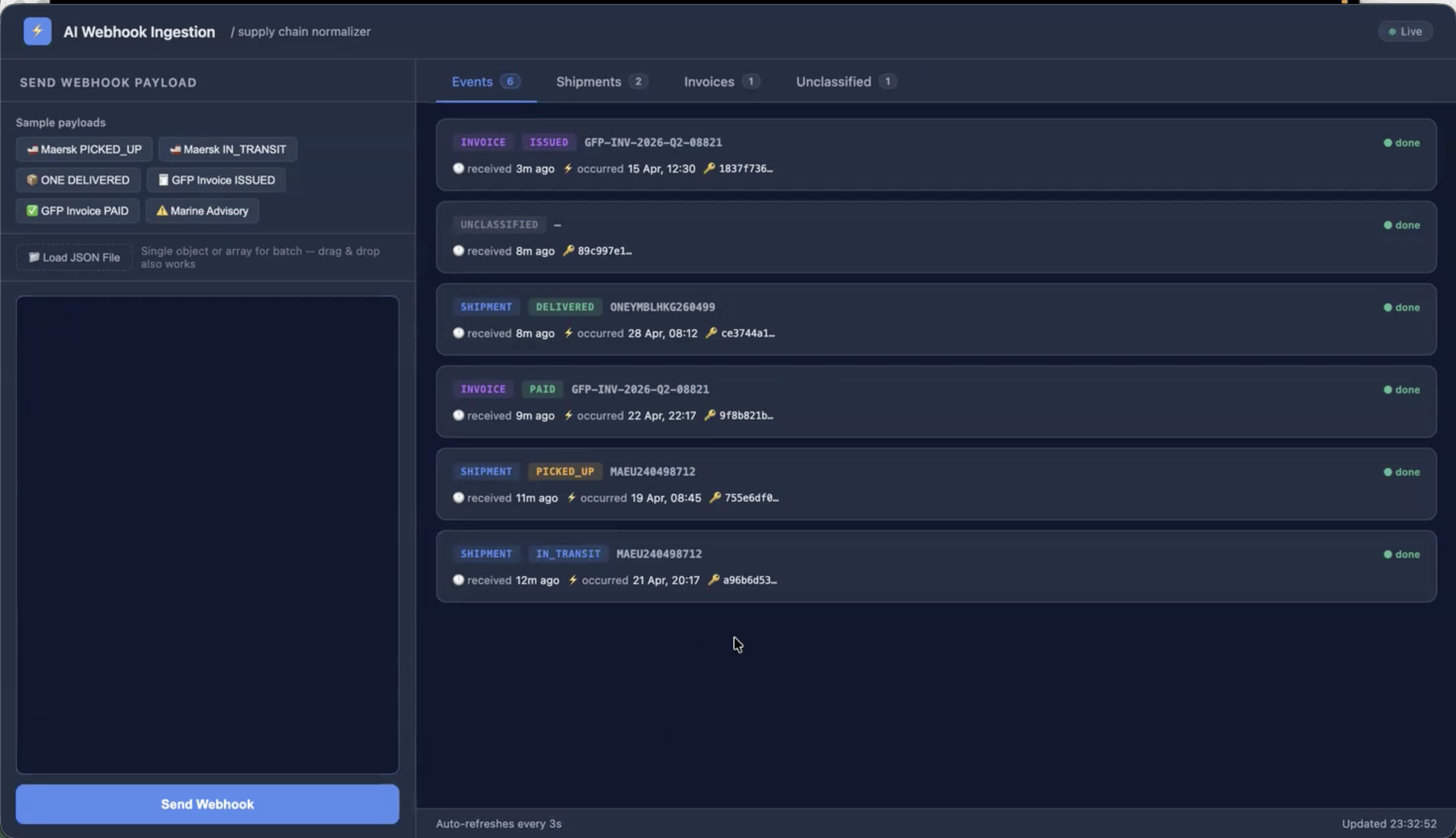
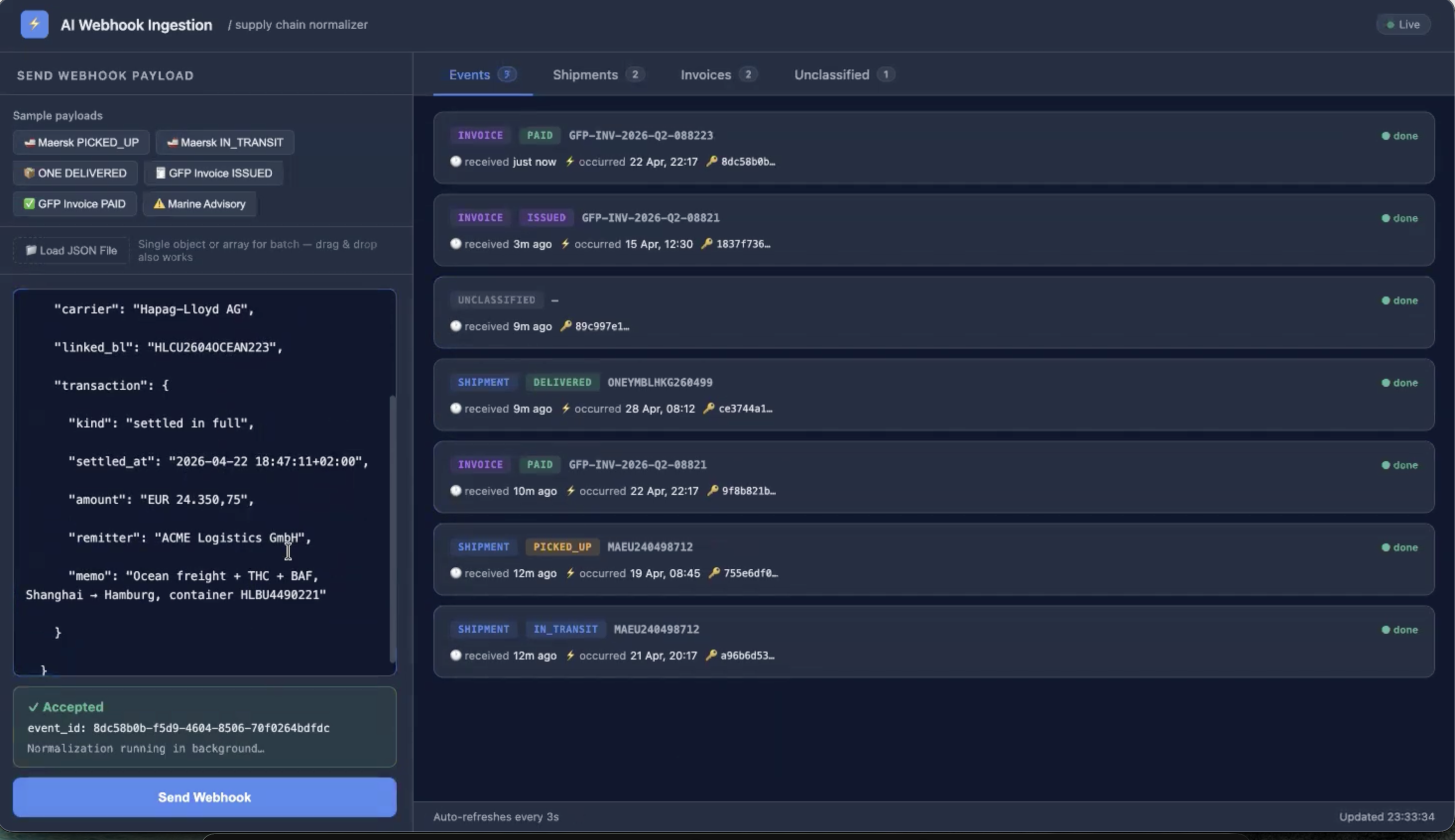
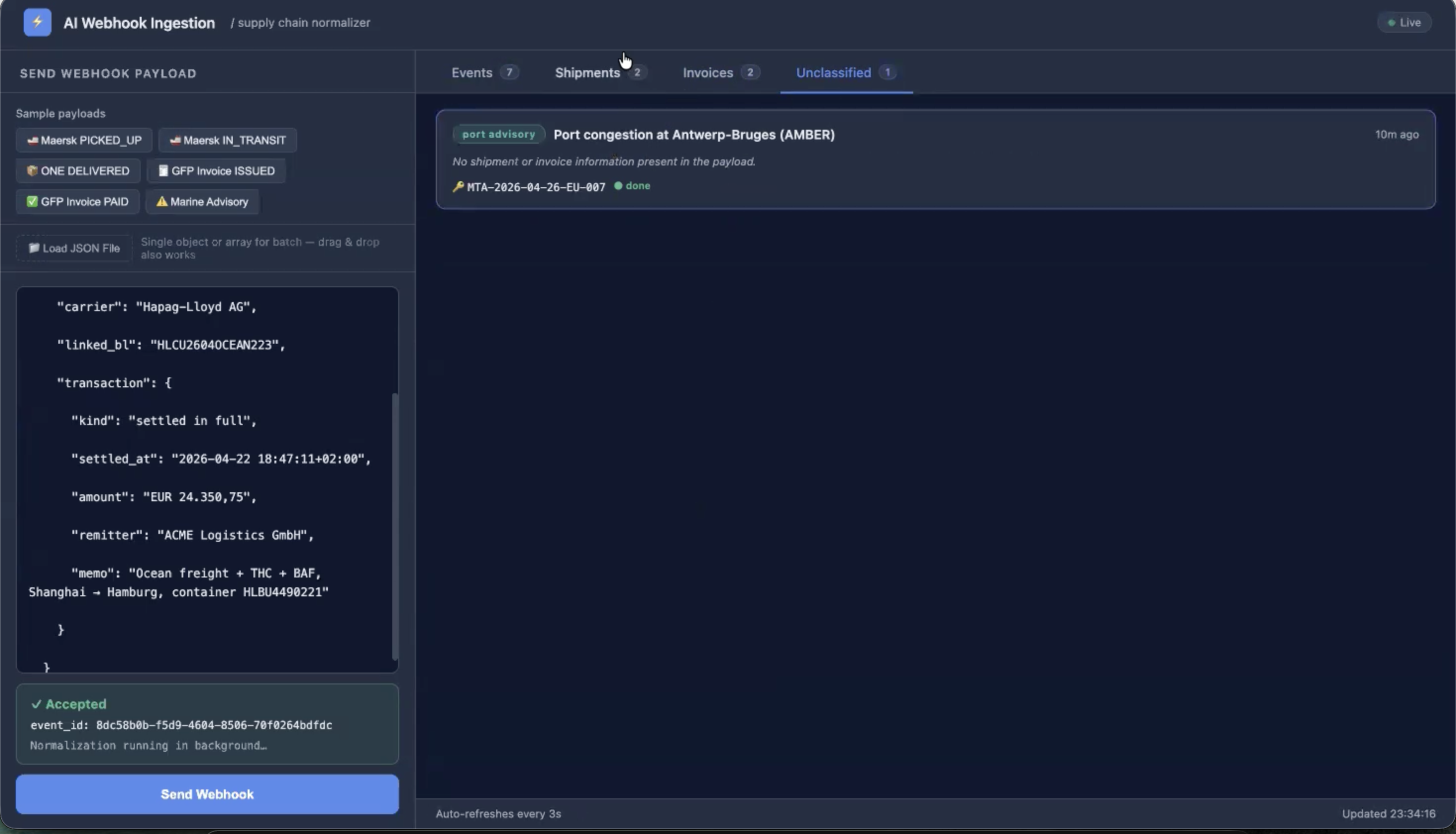
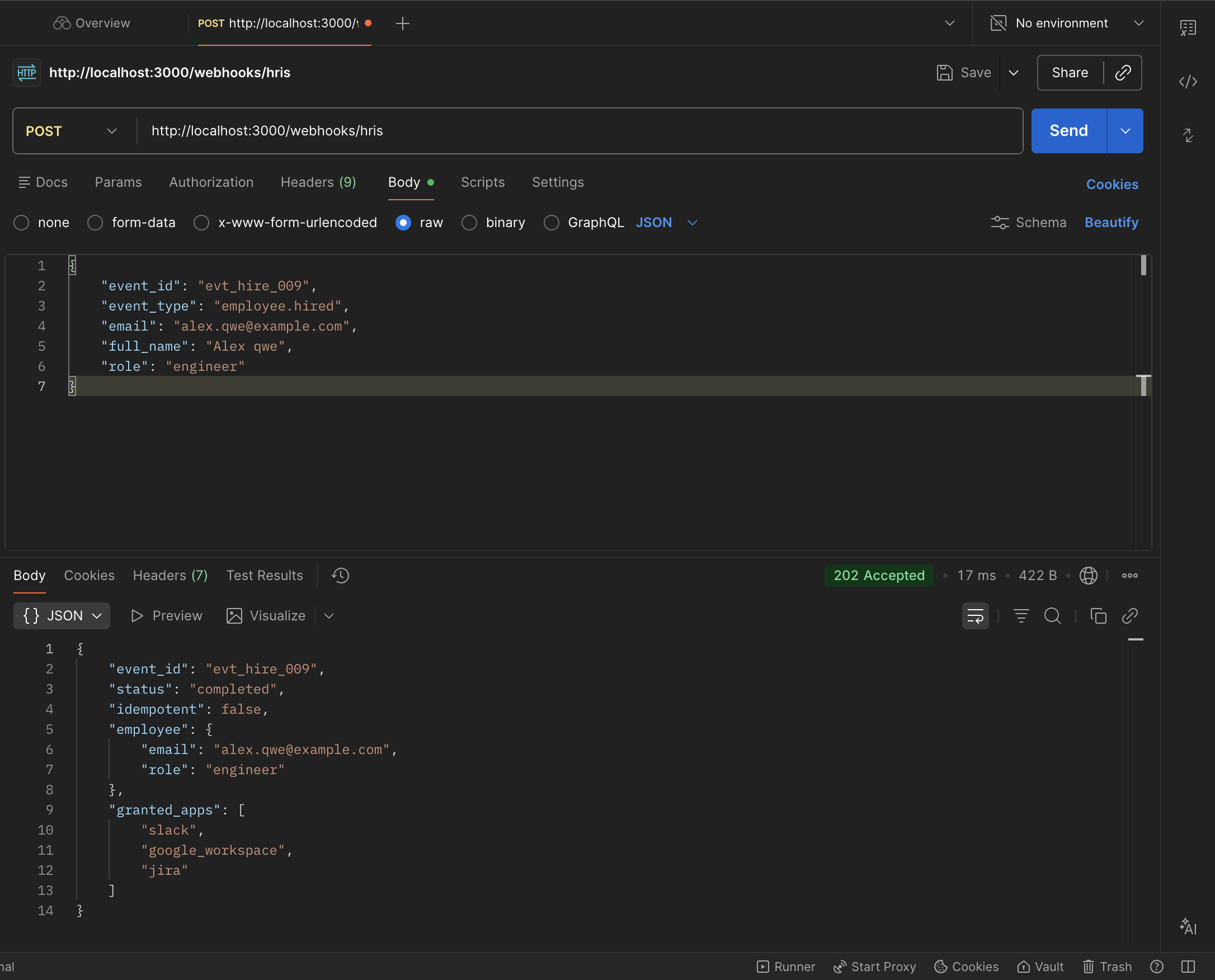
AI Webhook
Ingestion Agent
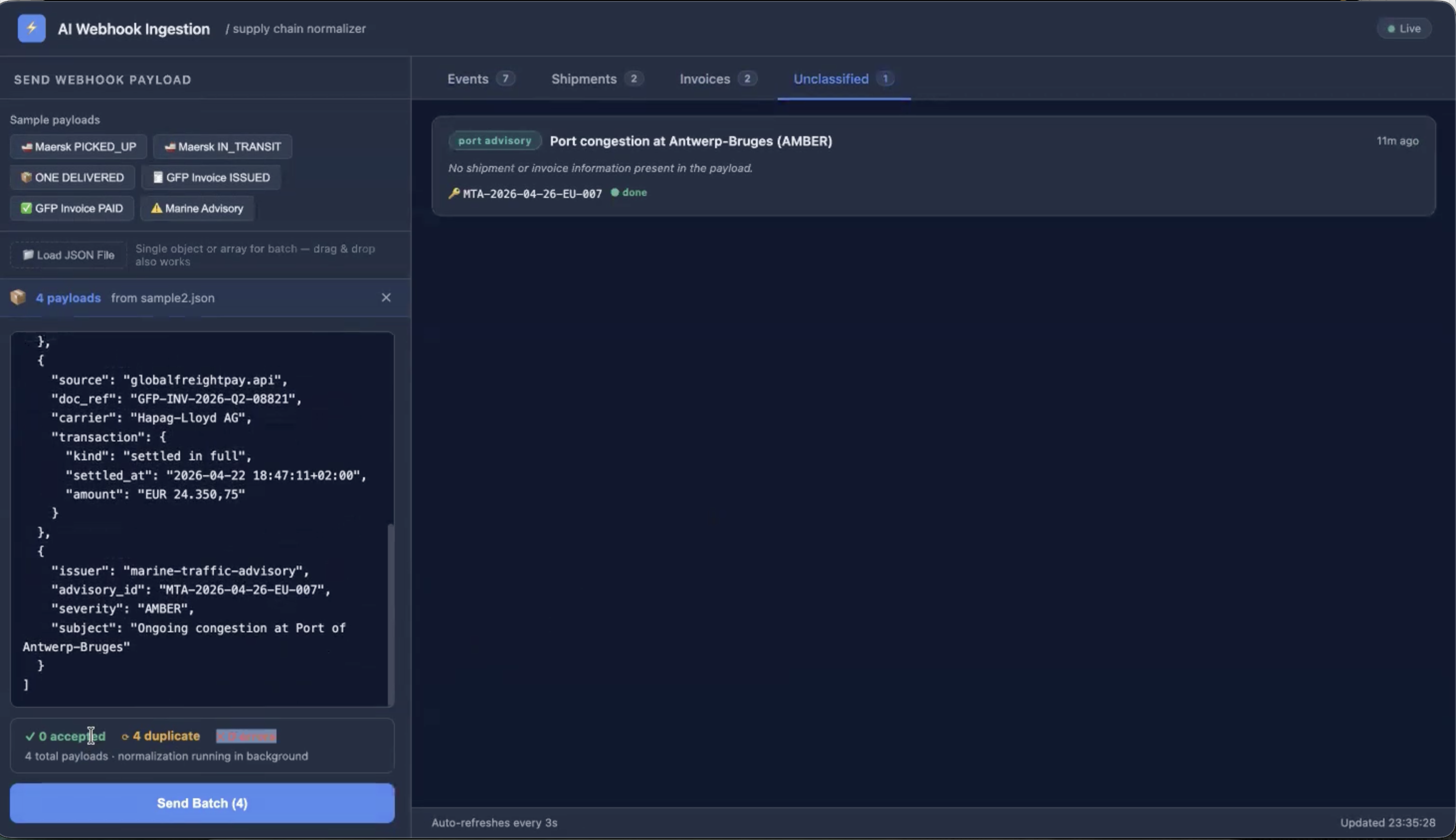
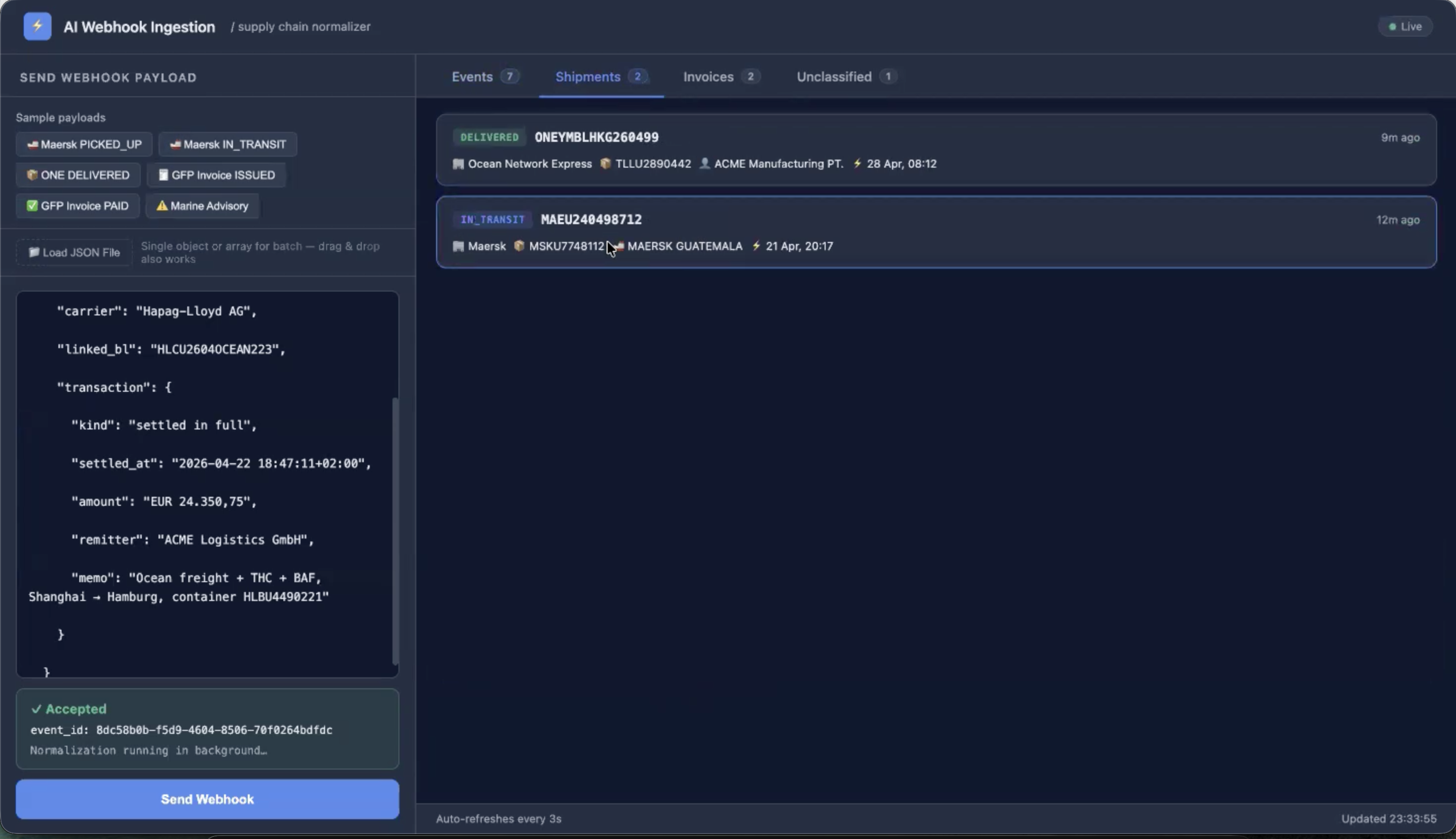
Real-time supply chain normaliser. Ingests raw webhook events from logistics providers, classifies them with LLMs, and writes typed schemas to PostgreSQL — all under 100ms vendor ACK.
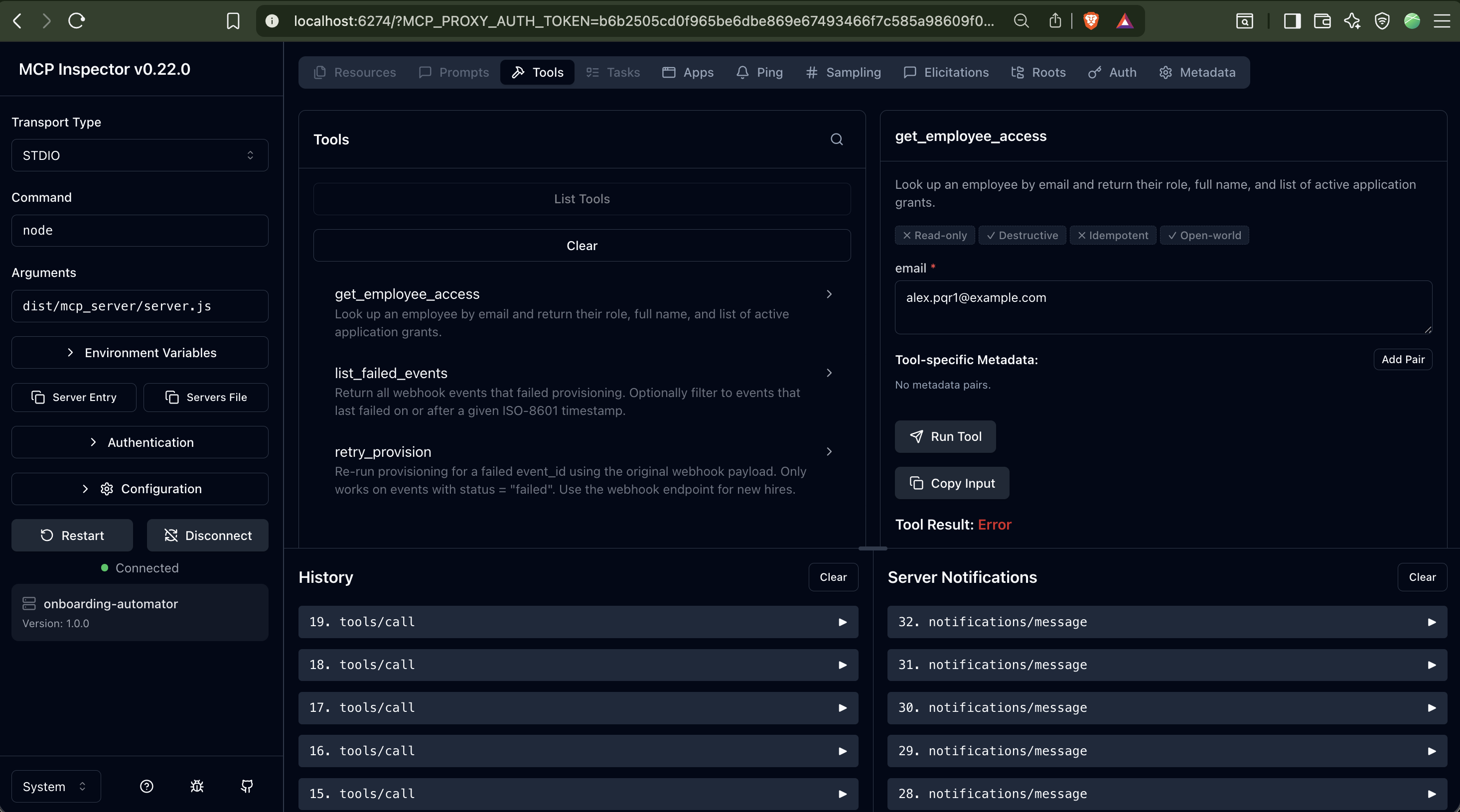
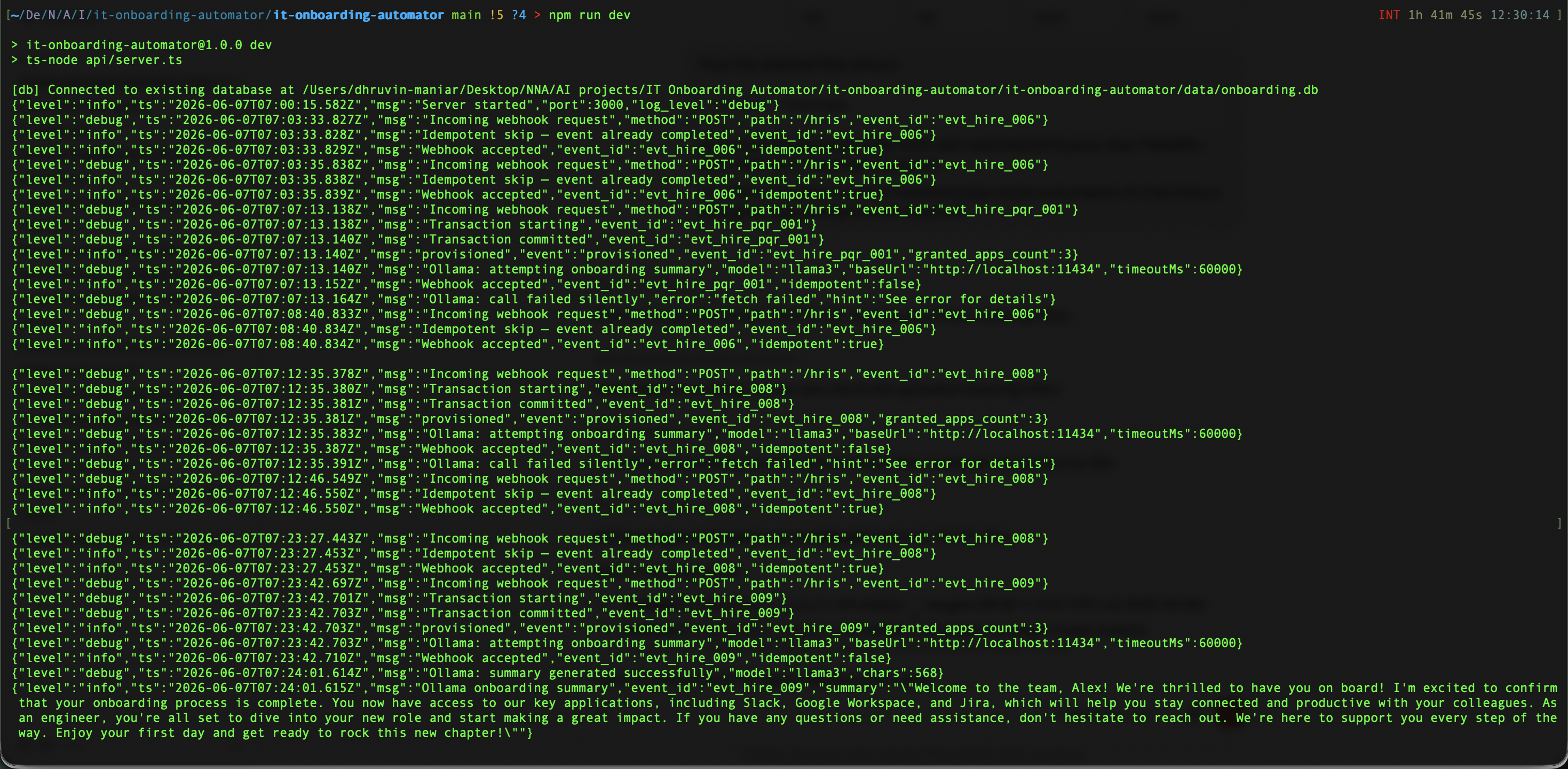
IT Onboarding Automator —
MCP Provisioning Agent
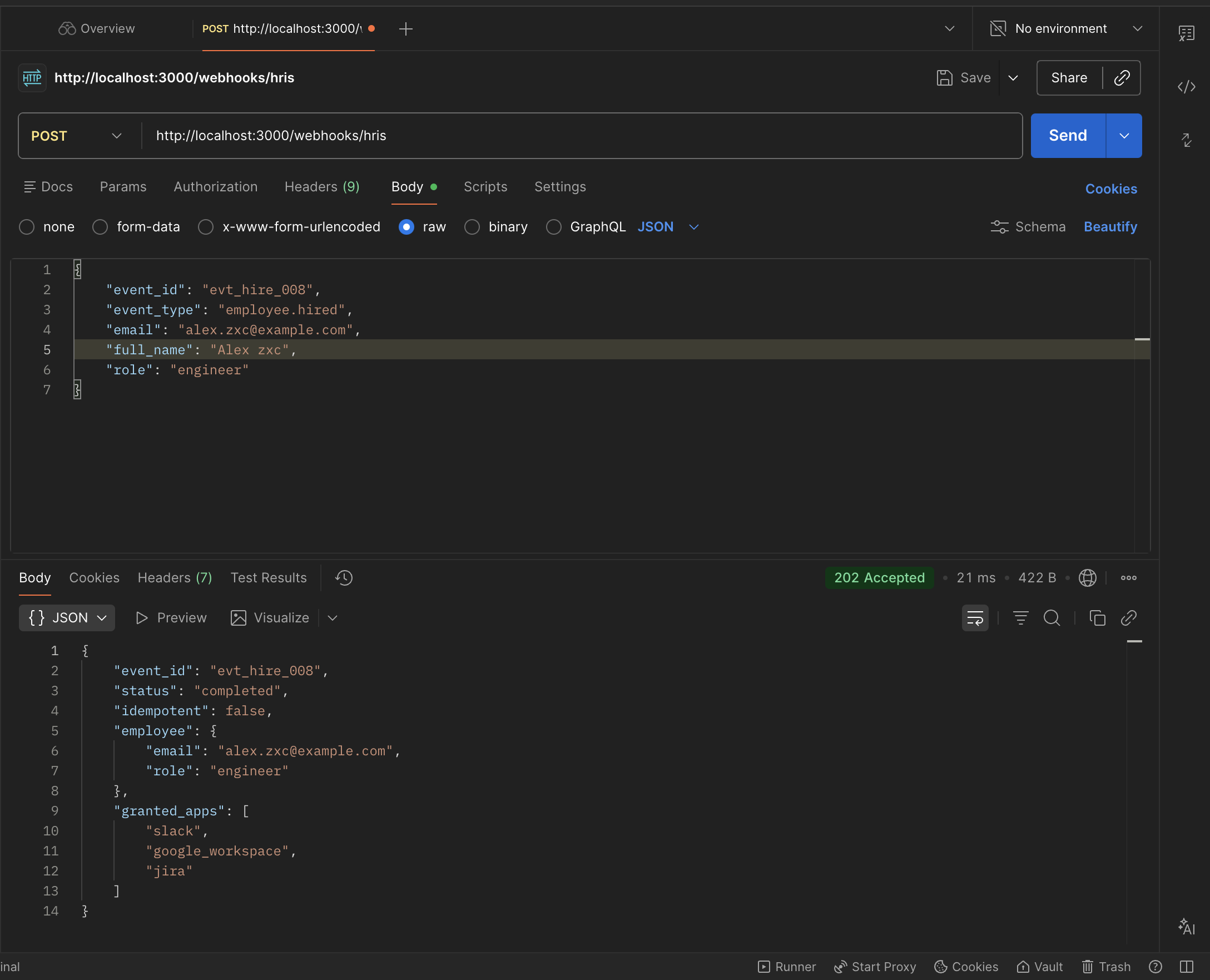
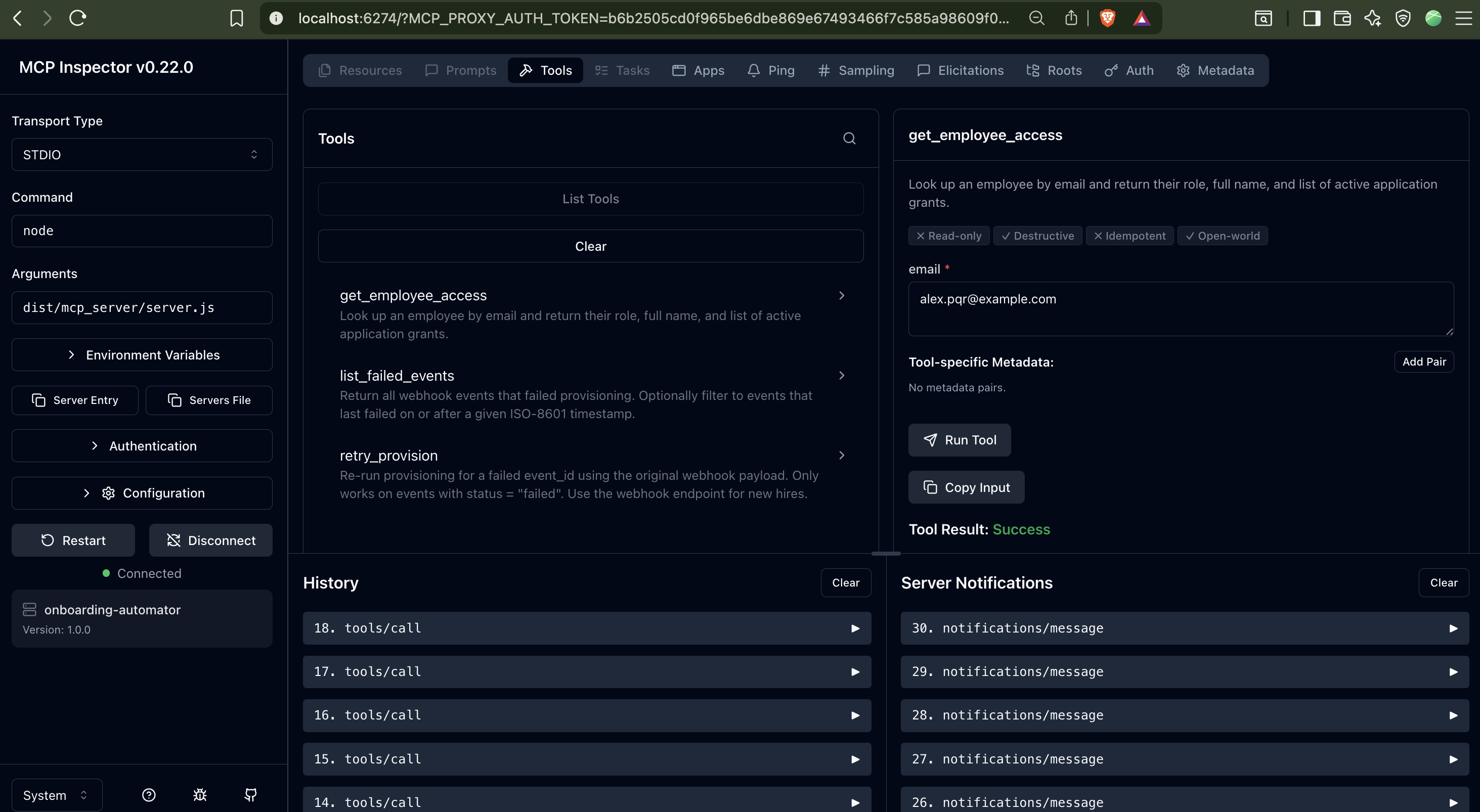
Spec-driven MCP provisioning agent built in Kiro. Exposes an MCP server with three agent-callable tools — lets an AI agent inspect access and retry failed events without direct DB access. Dual-delivery mode: HTTP API and MCP server share a single provisioner module with exactly-once state machine guarantees.
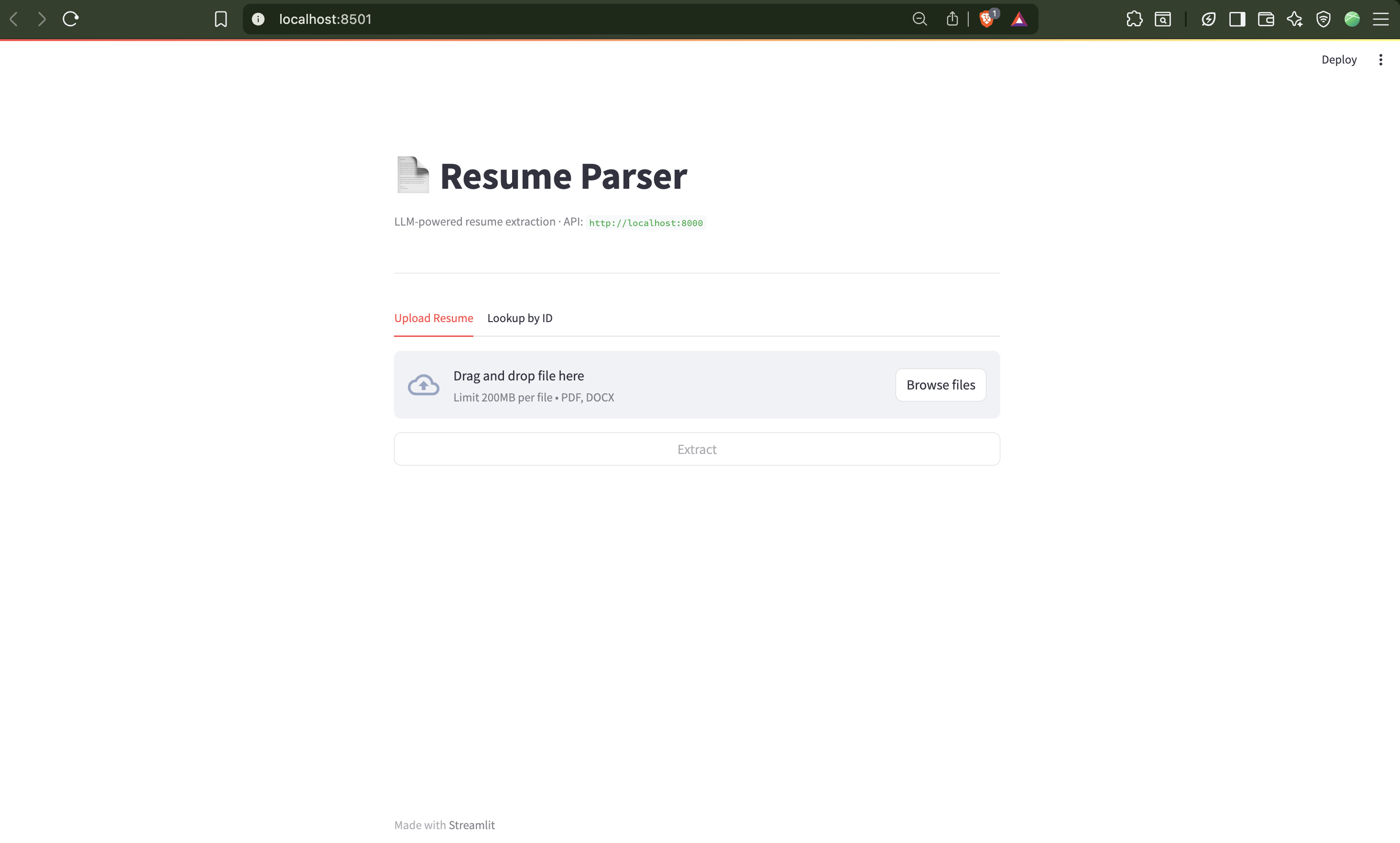
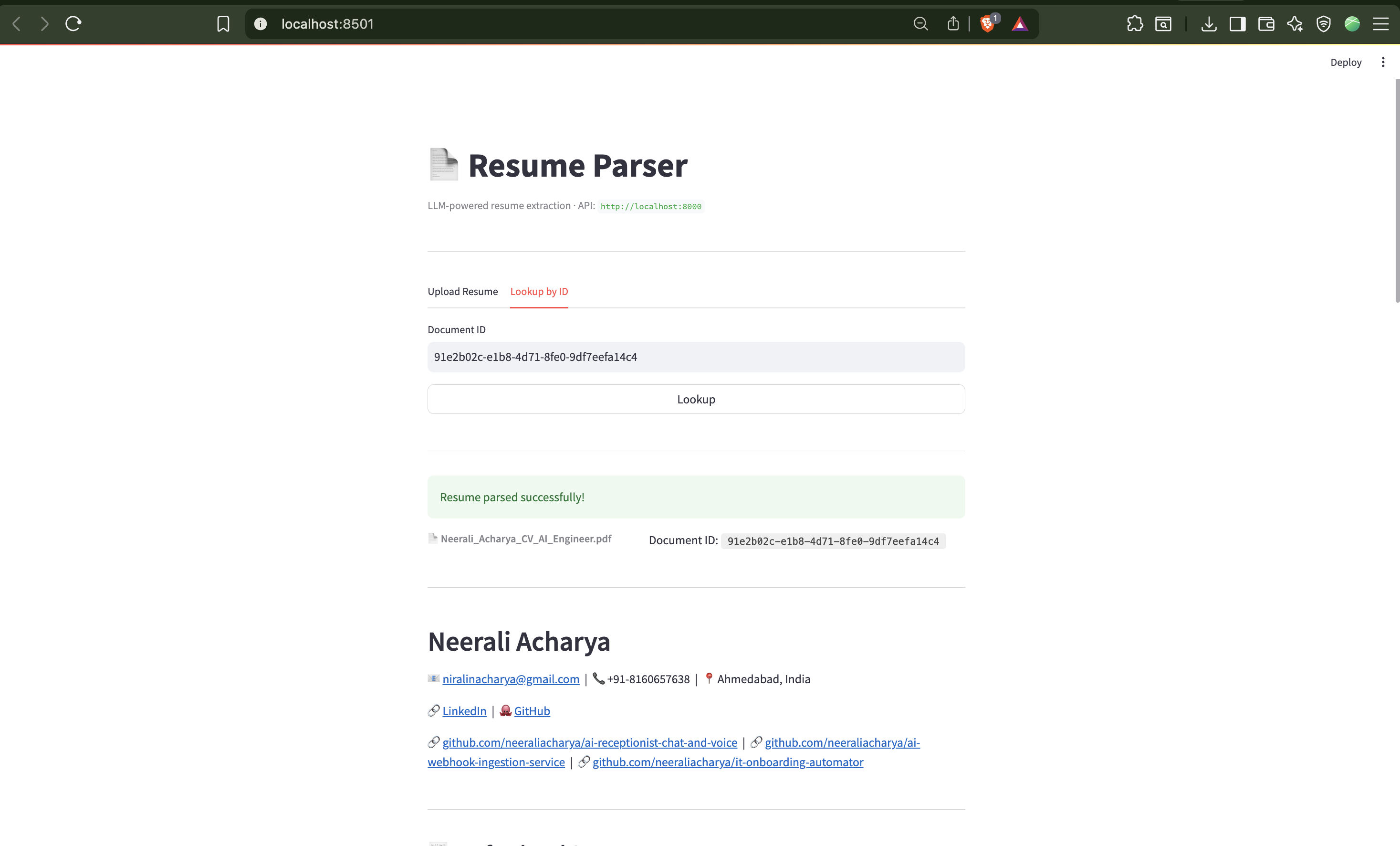
LLM-Powered
Resume Parser
Structured data extraction from PDF and DOCX resumes using a multi-provider LLM backend. Pre-processes documents with regex URL detection before LLM ingestion, implements self-repair retry on malformed JSON, and exposes results via FastAPI REST and a Streamlit UI — no external infrastructure required.

What I work with
Awards
Let's connect
Open to senior AI and backend engineering opportunities.